In my last post I talked about how I made a enjoyable little display of fireworks for the terminal. It was fun to make and it’s fun to watch when meetings get boring (always).
However after running my fireworks for a while, I started noticing some funky details. The fireworks could be a little flickery at times. And not in a good way.
Well we couldn’t have that! So it was time to investigate.
What do the flickers mean Mason?
The first thing I noticed was this wasn’t a problem on Linux, it only happened on macOS.
I do most of my development on a beefy Linux machine with 6 real cores (12 total threads) and figured perhaps this was just a specs thing, so I fired up my 7 year old ThinkPad running CentOS and still didn’t have flickering. Compared to my 2019 work MacBook, it was smooth as butter. Could this be a Mac only bug?
On a whim I remembered how iTerm is not the fastest terminal in the world and decided to try my fireworks on the slowest terminal I could think of. The WSL terminal.
I broke out my old Windows machine and after a half an hour, got WSL and fireworks up and running. The result:
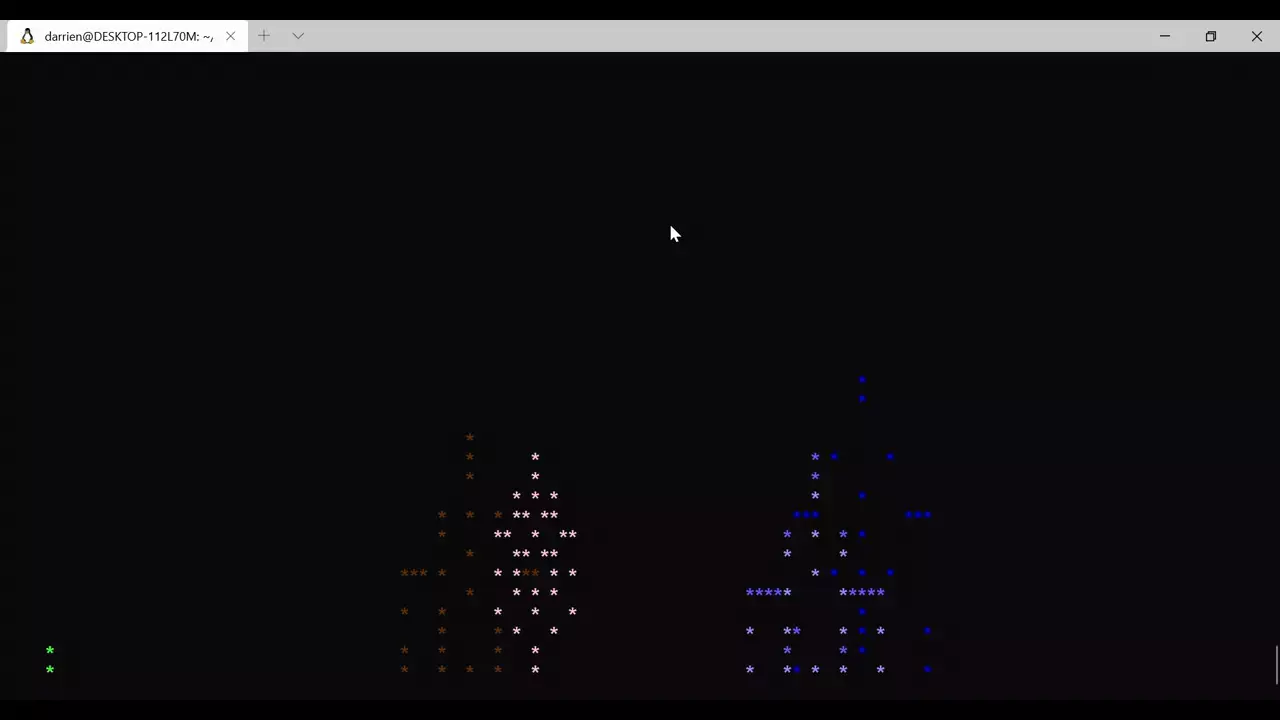
The Windows terminal running WSL exhibited the same behaviors as on macOS, but much more frequently and much more consistently. This lead me to believe that the problem was in drawing. I must not be doing it efficiently. Other terminal applications can run flicker free in Windows terminal, so why not me too?
The old firework rendering pipeline
The old rendering pipeline was very simple. It used two total threads, one for input, and one for all rendering work. This is a simple approximation of it:
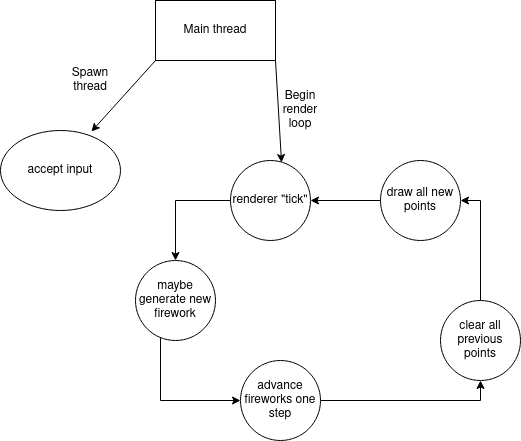
If you look at this for long enough, you’re going to see some low hanging fruit to optimize away.
- we’re making fireworks on the same thread we draw points
- we’re clearing way more points than we need to
- we’re drawing way more points than we need to
Let’s dig into each one individually.
we’re making fireworks on the same thread we draw points
The maybe generate new firework and advance fireworks one step happens before drawing every single time. In order to keep a consistent framerate, this would have to be completed in a fraction of a fraction of a second. I’ve done my best to optimize this as much as possible, but especially with the more exciting fireworks I plan on adding later, this won’t be possible in the future.
Firework generation and advancing should happen on another thread.
we’re [clearing|drawing] more points than we need to
The painting implementation is dumb as rocks, and simply:
- creates a list of every single point to be drawn
- creates a list of every single point to be cleared
This means on each loop, we draw points that were already on the screen, and clear points just to have them repainted shortly after.
Drawing is easily the slowest part of the application, so that’s not good at all.
How do we deal with this?
Given our two problems, I felt it would make the most sense to move as much of the actual firework building work to another thread. While overkill for how we’re currently figuring out the points we need to draw fireworks, if we move the work to another thread we’ll have time for all of the set logic required to only draw and clear the points that have changed.
The new architecture
The new architecture revamps a few things, but mostly just moves them around with the addition of a new compositor component.
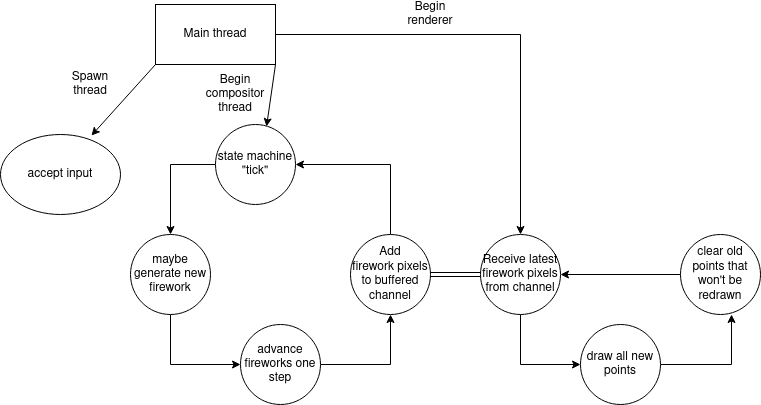
The compositor runs in a separate thread and sets up all the points required for all of the fireworks ahead of time.
Originally when planning up this v2 architecture I was only going to prep one frame of fireworks at a time, but then I figured, why do just one? Why not get a few ready ahead of time?
Rust has sync_channels which easily lets you do this. Set the max buffer size and it won’t insert more than that. For my Java folks out there, it’s conceptually similar to a LinkedBlockingQueue for sharing data across threads.
It’s just a regen buffer
At this point I was thinking myself very clever for coming up with such a new innovative idea. Imagine what others will think when I tell them about this cool new concept of async rendering!
I put my head down and tried to think of all of the other applications that might find this technique useful, only to realize… a lot of other applications already did something like this.
Distraught but still hopeful I had “really done something” I Google’d around only for my hope to meet its demise on the framebuffer wikipedia page.
In computing, a screen buffer is a part of computer memory used by a computer application for the representation of the content to be shown on the computer display. The screen buffer may also be called the video buffer, the regeneration buffer, or regen buffer for short. Screen buffers should be distinguished from video memory. To this end, the term off-screen buffer is also used.
Well so much for that.
Implementation
This post would be no fun without a bit of discussing how it was made. We can spend all day in the ivory tower talking about architecture, but entering the trenches and actually writing the code is a little different.
Channel setup
If you look at the v2 architecture diagram you’ll see there are 3 components now. I wanted to give them all a chance to shut down completely, so the component accepting input now takes a list of senders it will send request to kill signals to.
Likewise, we need to set up the buffer for which we can send fireworks to the renderer. This is all done like so:
|
|
A design decision I made here was to not have the compositor be spawned by the
renderer. I didn’t want the renderer to know anything about the compositor, just
that it will receive Drawables from some magic buffer. Who knows what’s
filling it!
Input capturer
This barely changes and isn’t really isn’t worth talking about. It has now been upgraded from an 18 line file to a 20 line file.
Poor input capturer; perhaps you’ll get a longer section in the future.
Renderer
The renderer changes in a few exciting ways, the most exciting in that it is gutted. No longer does it spin up a firework state machine to get Drawables, now it just waits at a channel, lonely and blocking until it gets some input.
|
|
Otherwise the renderer is the same. The goal of the renderer is to be as dumb as possible and it is certainly achieving that.
Compositor
Finally the compositor, which is 30 or so lines that really come down to: ticking the state machine and sending the points it made somewhere.
|
|
And that’s it for the new architecture components!
So then where are all the code changes??
There are only a few. Really, the bulk of the work was in architectural changes.
The final changes, the ones that affect drawing are in the firework itself. We can do a whole lot more work now that we can work in a separate thread, and so the Drawable trait we worked with in the previous post goes from:
|
|
to:
|
|
Looking at the two, you’ll see the first is infinitely faster and also does infinitely fewer allocations. And that’s how it was meant to be! As Drawables had to be ready in real time, the implementation had to be fast as lightning. But now they can take a little longer and do a lot more work. With async rendering, they can do (roughly) as much work as they like and still be real time!
All this extra work affords us some really slick optimizations. Post work we:
- paint exactly what has changed and nothing else
- clear exactly what needs to disappear and nothing else
These two things optimizations vastly increase the speed of drawing fireworks.
Downsides
Well there is one, and if a point is ever drawn over and then cleared, it will never be redrawn, meaning there can occasionally be small holes in the fireworks. Something like this happens when two fireworks collide.
Solving this wouldn’t be too hard, but the fireworks still look pretty nice and I think the asymmetrical nature of ones with little holes gives them some character.
So was it all worth it?
Well I’ll let the results speak for themself.
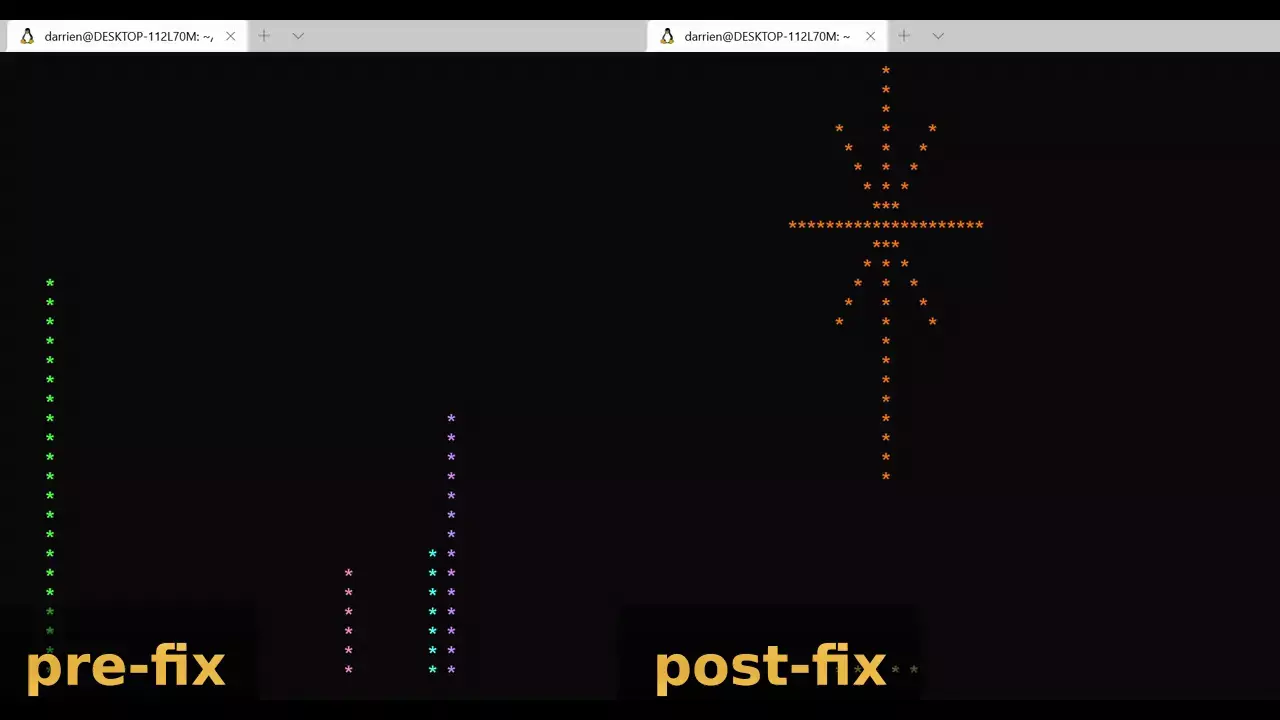
Thanks for reading! If you liked this post, feel free to check out my blog posts about the silly CLIs I made using rust :)
Fireworks source and binaries can be found here.